

The most exhausting part of building an online presence is not the writing. It is the visuals — the YouTube thumbnail that needs to look clickable but not cheap, the Instagram carousel that should feel cohesive without hiring a designer, the blog header that must match a brand palette you defined in a weekend. For solo creators, these assets usually mean spending hours in Canva or Photoshop, compromising on quality, or simply not publishing at all. AI image generators have promised to close this gap for years, but until recently the output was a gamble: beautiful compositions ruined by garbled text, inconsistent style, or a complete disregard for what you actually asked for. The platform at gpt image 2 is built around a model that appears to have changed that equation, and the practical question worth asking is not whether the technology is impressive in the abstract, but whether a person without a design background can sit down, describe a visual, and walk away with something publishable in under ten minutes. I tried to answer that question from the perspective of a solo creator who needs multiple asset types, consistent branding, and minimal friction between idea and output.
Why This Matters More Than the Leaderboard
Industry watchers will point to the model’s chart-topping score on the Image Arena blind testing platform, a gap of over 240 Elo points above the next competitor as of early 2026. While that number is eye-catching, it is the downstream behavior that changes how a creator works. The model accessible here uses an autoregressive token-based generation method rather than traditional diffusion pipelines, which means it treats image elements the way a language model treats words: sequentially, with each part conditioned on what came before.
The practical result is that the tool can not only draw a promotional graphic but also spell the headline correctly, place it in a logical layout, and maintain visual consistency across edits. For someone who does not have the vocabulary to describe lighting ratios or composition rules, simply writing what they want in natural language and getting a usable result is the real breakthrough.
A Workflow Built for Speed, Not for Learning Curves
The platform reduces image creation to three steps that mirror how a person already thinks about visual content: describe what you need, pick the output quality, and refine until it is right. There are no Discord commands, no model selection dropdowns, and no parameter sliders that assume technical knowledge. The interface is essentially a text field, a few dropdowns, and a generate button.
Step 1 — Brief the Model Like You Would Brief a Designer
The input box invites you to describe the image you want, and the platform’s own guidance suggests being specific about composition, style, colors, and any text that must appear. In repeated tests, I noticed that phrasing the prompt like a creative brief — “Instagram carousel slide for a productivity newsletter, clean white background, navy headline text saying ‘Three Systems We Tried in April,’ subheading in light gray, minimal illustration of a calendar” — consistently produced better results than keyword stuffing. The model responds to context and sentence structure, not just word frequency.
Giving It a Job Description Improves Output
One small tactic that proved effective was starting a prompt with the intended use case and format. Writing “Generate a 1:1 social media graphic for…” versus simply listing visual elements gave the model a clearer anchor, likely because it associates format with layout conventions learned during training. The platform itself does not prescribe this, but in my experience prompts that opened with the asset type and platform tended to produce more appropriate composition and spacing without needing explicit layout instructions.
Step 2 — Match the Technical Settings to Where the Image Will Live
Once the prompt is ready, you choose from the available resolution options — ranging from 1024×1024 up to 4096×4096 — and select an output format among PNG, JPEG, and WebP. A transparent background checkbox is also present, which outputs a PNG with an alpha channel. There is a practical nuance here that is easy to overlook but matters for real workflows.
Resolutions Are Not Just Numbers
A 4K image at 4096×4096 is appropriate for print merchandise, large banners, or situations where an asset will be heavily cropped by different platforms. For a Twitter post or an Instagram Story, that resolution is overkill and needlessly increases generation time. A standard 1024×1024 square or a landscape 1536×1024 served my needs for nearly every social test. The transparent background option, on the other hand, is genuinely transformative for anyone building a brand kit — overlaying generated elements onto colored backgrounds later without a manual background-removal step is a workflow accelerator that older AI tools did not reliably offer.
Step 3 — Edit Through Conversation Instead of Starting Over
Generation completes within seconds, and the image appears in the interface. If something is wrong — text slightly misaligned, a color off, an unwanted element in the frame — you do not need to craft a new prompt from zero. You describe the specific change in plain language, and the model re-renders accordingly. This conversational editing loop, sometimes called Smart Image Editing, is the feature that most clearly separates the platform from one-and-done generators.
Fixing a Graphic Without Touching a Design Tool
I tested this by asking the model to change a headline color from navy to forest green, remove a decorative icon that appeared unrequested, and replace a background gradient with a solid off-white. Each edit took one instruction and returned a revised image that preserved everything else in the composition. There were instances where fine details around the edges of a text change showed minor artifact remnants, but a second pass eliminated them. For a creator who does not own or know Photoshop, being able to say “make the text slightly bolder” and get exactly that is a practical superpower. The process is not instantaneous — complex edits took perhaps twice the time of the initial generation — but it is still faster than exporting, editing, and re-uploading through traditional tools.
Three Types of Assets, Three Real-World Outcomes
To ground this in actual creator tasks rather than laboratory prompts, I generated assets across three common solo-creator needs. Each test is evaluated for production readiness, not technical novelty.
Instagram Carousel Slide — Educational Content
The task was to produce a title slide for a carousel post about daily writing habits, requiring a large headline, a subtitle, a small author handle, and a style that felt consistent with a personal brand. The model output a clean layout with the headline “Write Like You Talk” in a modern sans-serif, a lighter subtitle beneath it, and the handle “@heyvernon” in the bottom corner. All text was legible. The composition left clear negative space around the text, which is exactly what you want for a slide that will be overlaid with the Instagram UI. A second slide requested with a numbered list inside the same visual style maintained the fonts, spacing, and color palette without needing explicit style-transfer instructions.
Strengths and Minor Flaws
The visual consistency across the two slides was high. The model appeared to retain the aesthetic choices from the first generation when prompted for a second slide “in the same style.” The only noticeable variation was that the second slide’s text shading was ever so slightly lighter than the first — imperceptible on a phone screen but visible when pixel-peeping. For a creator publishing a ten-slide carousel, a batch generation with a final manual alignment check would be prudent. The platform supports this iterative flow well enough that producing a full carousel in a single sitting felt realistic.
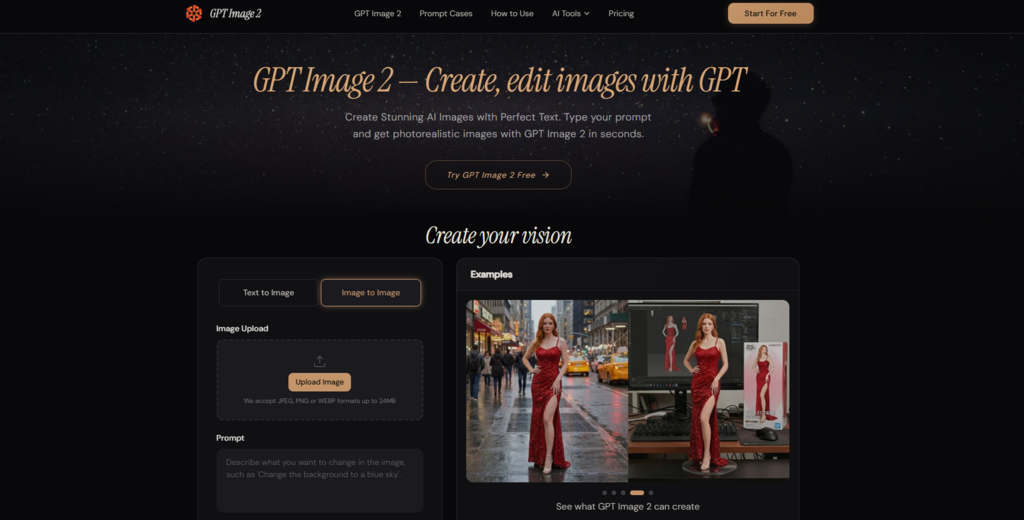
YouTube Thumbnail — High Contrast and Emotional Hook
Thumbnails are arguably the most demanding social visual because they must be readable at a tiny size and emotionally immediate. I asked for a thumbnail featuring a person’s face with an expression of surprise, a bold yellow text overlay reading “This Changed Everything,” and a blurred background suggesting a workshop setting. The result placed the face centrally, rendered the text in all-caps yellow with a subtle dark shadow for legibility, and blurred the background in a way that pushed attention forward. The facial expression was readable as genuine surprise rather than a contorted grimace — something previous AI models frequently got wrong.
The Text-on-Skin Challenge
One recurring issue in thumbnail design is text overlapping skin tones or patterned clothing, which can make letters unreadable. When the generated text sat partially over the subject’s shoulder, the contrast held, but the edge of the letters softened just enough to lose crispness at very small sizes. A quick conversational edit to shift the text slightly upward resolved it. Users who need thumbnails to pop at mobile sizes should plan for that kind of micro-adjustment, but the fact that it is possible without leaving the platform is notable.
Blog Header Image — Branded Visual with Subtle Text
The final test asked for an abstract illustration for a business article, with a soft gradient background in brand-adjacent teal tones, minimal geometric shapes, and the article title “Remote Work Is Not the Problem” rendered small in the corner as an overline. The output was aesthetically restrained — no excessive decoration, clean shapes with soft shadows, and the title text at exactly the weight I described. This kind of asset is rarely worth hiring a designer for. With this tool, it took roughly three minutes from typing the prompt to downloading the final file.
Where Abstraction Works and Where It Does Not
Abstract prompts gave the model creative latitude that it handled gracefully, often producing compositions that felt intentional rather than accidental. However, when I attempted a highly specific geometric pattern — a repeating interlocking hexagon motif — the model approximated the pattern but introduced slight inconsistencies in the shape repetition. This suggests that mathematically precise patterns are still near the model’s edge, and users needing such precision may need to generate and then refine through a vector tool.
Capability Snapshot for Solo Creators
The table below compares how this platform supports common solo-creator workflows relative to the previous generation of tools — not against professional design suites, but against what an individual without design support would have reasonably had access to.
| Workflow Requirement | This Platform’s Behavior | Previous AI Image Tools |
| Text-Embedded Graphics | Accurate multi-line text in varied placements; minor errors uncommon but possible | Text was unreliable; posters and thumbnails often required external editing |
| Brand Style Consistency | Maintains palette and font feel across related generations with contextual prompting | Style drifted noticeably between outputs; required precise seed or reference image handling |
| Conversational Refinement | Edit instructions in plain English; no masks, layers, or re-uploading needed | Changes required regenerating from a modified prompt or exporting to a separate editor |
| Format and Resolution Control | Direct selection of up to 4K, multiple formats, and transparent PNGs | Variable; often capped at lower resolutions; transparent backgrounds not universally supported |
| Learning Investment | Near-zero — the interface mirrors a search bar with a few visible options | Often required learning Discord bots, parameter syntax, or prompt engineering techniques |
What You Should Know Before Depending on It
No review that skips the friction points is honest. Here is what I encountered across multiple sessions.
First, prompt precision is a requirement, not a suggestion. A loose prompt like “cool Instagram post about productivity” yielded a visually pleasant but generic result that would blend into any feed. Specificity is the price of differentiation. The model is capable of producing distinctive output, but it will not do so unless you tell it what distinctive means in your context.
Second, generation speed is subject to queue variability. While the platform states a few seconds per image, there were moments when server-side load appeared to extend wait times to around fifteen seconds. This is still fast compared to older tools, but it is not a guaranteed sub-five-second experience every time.
Third, the output is consistent but not duplicable. Generating the same prompt twice can yield images that share a family resemblance — similar fonts, similar layout logic — but are not pixel-identical copies. For brand environments that require strict templating, this means you will likely use the tool as a first-pass generator and then standardize in a template tool if absolute consistency is needed.
Finally, the platform is a third-party interface, not an official OpenAI product. It states on its site that it does not permanently store user images or prompts, and that uploaded files are deleted within one hour. These are the right commitments, but they are not audited independently. Creators working with pre-release product visuals or sensitive client material should evaluate that risk in their own context.
Who This Workflow Was Built For
The solo content creator who publishes across platforms, the newsletter author who needs a visual header per edition, the small business owner managing their own social presence — these are the people for whom this tool changes the production economics. The value is not in replacing a designer but in making it possible to publish visually coherent content on days when a designer is not available, which for many is every day.
What stood out across all my tests was not a single perfect image but the absence of a specific friction: the moment when you look at an AI-generated visual, sigh because the text is unreadable, and open Photoshop to fix it. That moment did not occur once during this evaluation. The platform at gpt image 2 is not magic, and it will not turn a vague thought into a brand-defining visual without effort. But for the creator who knows what they want and needs it delivered in a format that is ready to publish, the gap between description and usable asset has shrunk to something that fits inside a browser tab.